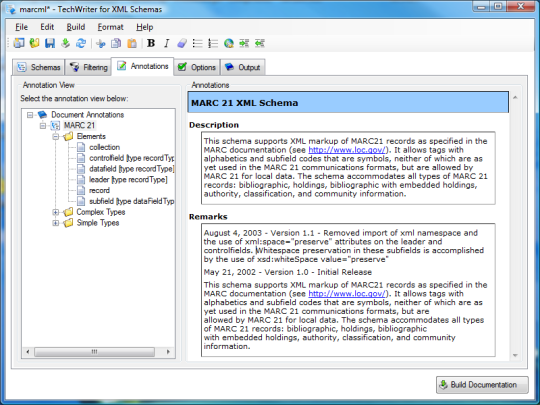
每個開發人員大量的XML文件的工作不可避免地運行到如何快速,方便地找到這些文件中的信息的問題。傳統的文字搜索功能,只要簡單的查詢去,但它沒有考慮XML的樹型,信息豐富的結構優勢。這很像運行針對數據庫的文本搜索,而無需使用SQL的力量。想像一下,你有成千上萬的XML文件,有關書籍的信息。對於像發現寫的是一個給定作者的文本搜索可能會做這項工作的所有的書簡單的查詢。但它屬於一旦短,我們使搜索更有趣一點,加入了一些條件,比如“YY後寫”或“成本不到$$”。然而,通過編寫一個簡單的XPath查詢的信息可以在幾秒鐘內找到://書[(@作者='理查德')和(@Year> 2002)和(@price <20)]
要求:
在Windows 2000 / XP / 2003服務器,Microsoft .NET框架2
限制:
30 - 天試驗
評論沒有發現