軟件截圖:
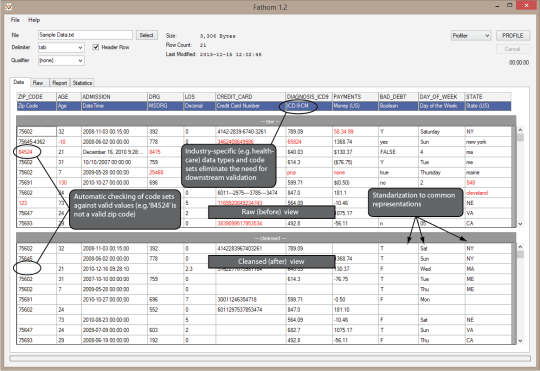
捉摸型材,淨化和規範源數據文件。它簡化了格式發現過程,使用戶能夠迅速地將數據轉換成更有用的形式,而不必訴諸於費時的ETL或數據庫的操縱。通過利用一組豐富的上下文數據元素,捉摸能夠識別,驗證和標準化了廣泛的一般和醫療保健的特定字段,例如郵政編碼,ICD-9和-10診斷和程序編碼,以及許多其他的。這在很大程度上消除了需要編寫代碼映射和/或通過分析引擎之前,驗證輸入數據庫負載或消費。此外,英尋的分析能力,旨在提供接近即時洞察本質和新文件的完整性,無論大小,通過抽樣的記錄的子集(雖然完整文件的分析是可行的)。外地人口率,不同的價值和行數,無效的條目的例子,數理統計(最小值,最大值,平均值,總和等)和許多其他特徵都顯示為異形的每個文件。所有需要作出承諾分析處理之前通過/不通過的數據判定中的信息,或寫入用於進氣導入腳本到一個數據庫,迅速與加速數據發現過程的目標產生的。
限制:
30天試用

評論沒有發現