PDF文本的OCR轉換器的命令行可以從掃描的PDF識別字符和提取圖像的文字與光學字符識別技術文本文檔中的文本。命令行應用程序是很方便的實現批處理腳本用,並且還提供了方便的手動有效控制選項。光學字符識別(OCR)是匝印刷或書寫文本到電子基於字符的文件中的視覺識別過程。被掃描並轉換成PDF文檔的文檔提供了基礎,而字符識別軟件可以解釋每一個人物形象上的PDF,並為其分配,然後可以進入到一個可編輯的格式,如文本的電子基於字符的文件或Word文檔。
許多文檔都存儲在掃描的PDF,這實際上是在圖像格式。這些文件是不容易的存檔或索引。 PDF文本的OCR轉換器CMD是一個好幫手識別掃描的PDF單詞和文本。
b.Extract從文字到圖像文件文本
要複製或編輯文本從掃描儀,甚至照片創建的文檔始終是費時。該應用可以識別與OCR技術,這將節省你很多時間來處理圖片中的文字信息圖像文字。
c.Easy命令行操作和批處理
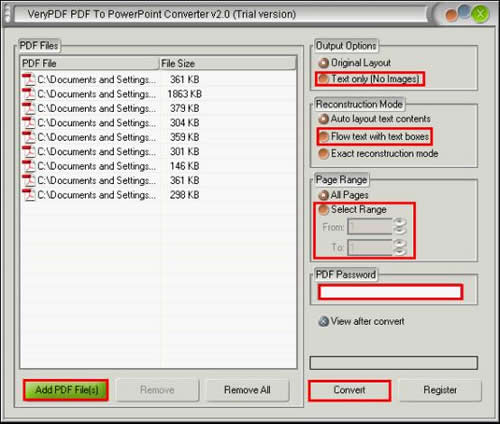
這是一個命令行應用程序,它是很方便的實現批處理腳本使用。命令行應用程序還提供了方便的手動有效控制選項。隨著命令,批量和手動控制是容易的。
PDF的功能,以文本的OCR轉換器的命令行:
1.Convert的掃描的PDF為可編輯的文本文件。
2.Recognize字符圖像,例如TIFF,BMP,PNG,JPG,PCX,和TGA。
3.Convert規定(從信息的網址下載語言包)的源文件的網頁。
4.No需要一個第三方的PDF閱讀器應用程序。
5.Support十餘種語言。
能進行良好保留PDF源文件的原始佈局。
7.Able轉換成PDF閱讀與佈局順序為文本。
8.Support命令行操作,這是對批處理過程是有用的。
限制:
100使用的試驗
評論沒有發現