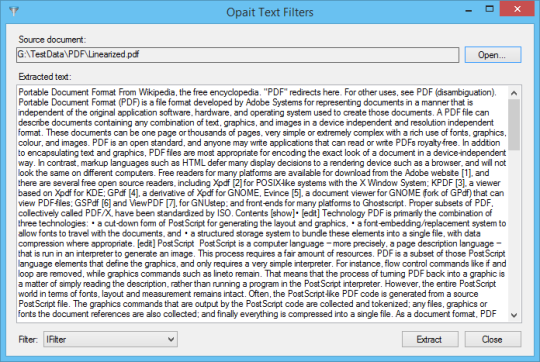
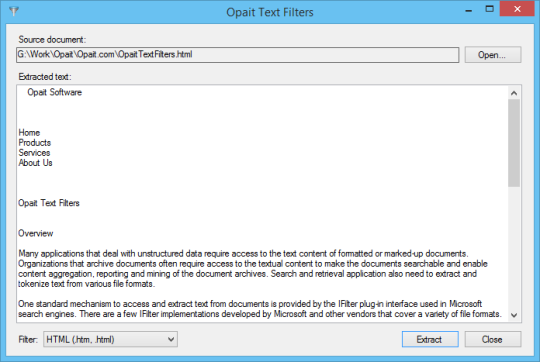
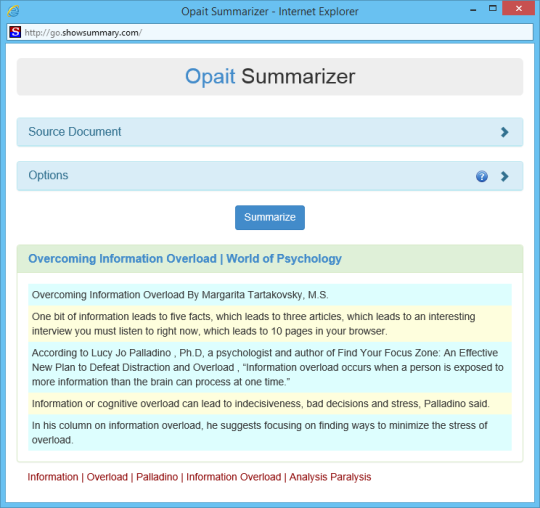
軟件截圖:
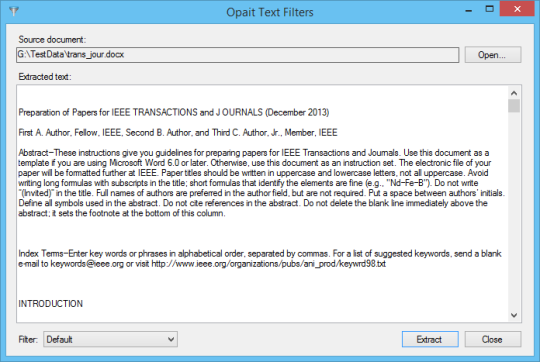
是處理非結構化數據
許多應用程序需要訪問的格式化或標記的文檔的文本內容。該歸檔文件組織經常需要訪問文本內容,以使文檔搜索,使內容聚合,文件檔案的報告和開採。搜索和檢索應用程序還需要提取和記號化,從各種文件格式的文本。
訪問和提取的文件的文本的一個標準的機制是由微軟的搜索引擎所使用的IFilter的插件接口提供的。還有微軟和其他廠商開發了一些IFilter的實現,涵蓋多種文件格式。在多個IFilter的開發標準或可靠性和文本提取質量參差不齊。
Opait文字過濾器是與其他主機以及一個直接與文件格式而工作,並改善了默認的IFilter實現一些自定義文本提取過濾器上已經安裝了一個簡單的接口IFilter的一個小工具程序。
。提取文本的接口是由被包括並且可用於文本過濾器集成到.NET應用程序的小類庫稱為Opait.Filters提供
<強>要求
的.NET Framework 4.5
評論沒有發現